


ABOUT THE PROJECT
GETTING THE DATA RIGHT What if we had a single point of entry to climate data for all products in the world? The aim of Getting the Data Right is to establish exactly that, and the goal is not as farfetched as one might think. |
|


The goal of project IL-402104209 is to create a software tool for automatic processing of information retrieval systems (Google, Yandex, Google Translate) for the Uzbek language. This tool involves the development of the morpholexicon and morphological analyzer for the Uzbek language. Additionally, the project aims to describe the scientific articles published in national and international journals as part of its implementation and to publish the printed version of the morphological dictionary.
This project was awarded in the "Women's Grants for Science" competition in 2021 and is funded by the Ministry of Higher Education, Science, and Innovation of the Republic of Uzbekistan. The project is planned to be implemented from 2022 to 2024 with a budget of 1,200,000,000 Uzbekistani soms.
The project's brief description includes the creation of an automatic processing tool for information retrieval systems (Google, Yandex, Google Translate) for the Uzbek language, focusing on the improvement of the quality of automatic translation, machine translation, and the ability to perform automatic morphological and semantic analysis on corpus units.
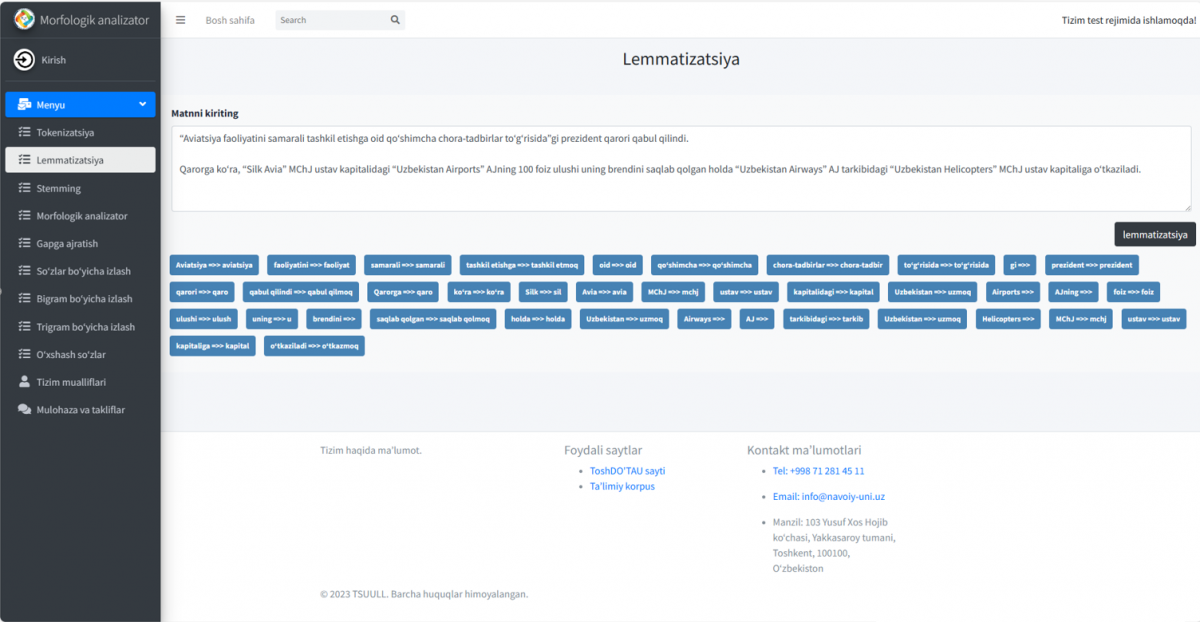
The expected outcomes of the project include the development of a morphological database for the Uzbek language, the creation of automatic processing tools, and the improvement of machine translation quality. The project also aims to contribute to the development of natural language processing technologies for the Uzbek language and enhance the quality of information processing in systems like Google, Yandex, and Google Translate.
Project Leader: Dr. Shahlo Mirdjonovna Hamroyeva, Doctor of Philology (DSc), Associate Professor. She has published 69 scientific articles in Scopus-indexed journals in the past few years.
The project has received three patents for the creation of national language corpora.
Published Monographs:
"Linguistic Support for the Uzbek Language Morphological Analyzer" - Tashkent: Globe Edit, 2020. ISBN: 978-620-0-61728-6
"Fundamentals of Creating a Linguistic Database for the Morphological Analyzer of the
Uzbek Language" - LAP LAMBERT Academic Publishing, 2021. ISBN: 978-620-3-19504-0
"Linguistic Foundations of Creating the Uzbek Language Authorship Corpus" - ISBN-10: 6200515077; ISBN-13: 978-6200515070, GlobeEdit (February 7, 2020); 260 pages.
About the Implementing Organization: Alisher Navo’i Tashkent State University of Uzbek Language and Literature was established in 2016. In 2018, it signed an agreement to merge with the Institute of Uzbek Language, Literature, and Folklore of the Academy of Sciences of Uzbekistan, forming a joint institute. Additionally, academic lyceum and experimental-testing laboratory were established as part of the university's expansion.
PARTNER UNIVERSITY
Istanbul Technical University, one of the oldest technical universities of the world, was established with the name of “Mühendishane-i Bahr-i Hümayun” by Sultan Mustafa the Third. The first technical university of Turkey, İTÜ is identified with the education of engineering and architecture. İTÜ pioneered the innovation movements during the Ottoman Empire period; and left its mark on the development, modernization and managementof the country during the Republic period. İTÜ contributed with all efforts in every aspect of Turkey’s cities and anywhere in villages; with roads and bridges, factories and dams, communication networks and power plants. In addition to contributing to the development of the country for more than 2 centuries with brainpower, İTÜ has left marks in many areas by raising countless scientists, businesspeople, politicians and bureaucrats.